本周最值得关注的论文TOP10|11.27

本周AI领域最值得关注的10篇前沿论文分享:讲述认知模型、多模态、具身智能、Agent、Benchmark等多个领域,针对每篇文章进行深度解读。
本分享来自奇绩行前沿信号:依托奇绩行内部的研究体系,持续追踪并解读全球AI领域前沿的论文和产品动态。内容由奇绩行研实习生整理。
因篇幅有限,本文仅展示部分论文阅读内容,欢迎扫码获取完整阅读文档。

全文目录
认知模型
MIT与英伟达提出FlashMoBA:通过信噪比理论优化块稀疏注意力,实现14.7倍加速
上海AI Lab P1团队发布P1模型:首个在国际物理奥林匹克竞赛中夺得金牌的开源AI模型
OpenAI提出权重稀疏Transformer,实现前所未有的人类可理解电路
多模态
腾讯混元与浙江大学联合提出Part-X-MLLM,通过统一程序化语言接口实现对3D物体的部件级理解与编辑,达成多任务统一
具身智能
Physical Intelligence 发布π*0.6 VLA模型,利用RECAP迭代离线强化学习方法,实现在真实任务中效率翻倍,故障率减半
复旦大学、创智学院邱锡鹏老师OpenMOSS团队等提出OpenMOSS SRPO,通过自参考策略优化实现视觉-语言-动作模型的新突破
NVIDIA发布VIRAL框架:实现人形机器人视觉移动操作的大规模仿真到现实迁移
Infra
Meta与Fireworks发布SilverTorch:基于GPU的统一推荐系统,实现23.7倍吞吐量提升和13.35倍成本效率优化
Agent
创智学院刘鹏飞老师团队与腾讯混元发布GeoVista:首个基于网络增强的Agent视觉推理地理定位模型,在多项指标上达到GPT-5和Gemini-2.5-flash水平
Benchmark
上海人工智能实验室与复旦大学联合发布MedBench v4:全国首个覆盖70万+题目、支持LLM/多模态/Agent三轨评测的中国医疗AI基准平台,揭示当前模型临床就绪度的系统性差距
认知模型
MIT与英伟达提出FlashMoBA:通过信噪比理论优化块稀疏注意力,实现14.7倍加速
信号源:麻省理工学院,英伟达
通讯作者:Song Han
论文链接:Optimizing Mixture of Block Attention
项目链接:https://github.com/mit-han-lab/flash-moba
跳转日报:奇绩前沿信号 11.18【语音版】
| 认知提取 就像在拥挤的图书馆里找一本特定的书,不必逐排翻阅,而是先看每排的标签找到正确的书架——FlashMoBA通过让注意力机制只关注最相关的信息块,而非处理所有内容,既提升了准确性又大幅降低了计算成本。 |
论文摘要
MIT和英伟达的研究团队针对大语言模型处理长上下文时的计算瓶颈,提出了FlashMoBA优化方案。该研究首次建立了块混合注意力(MoBA)的统计模型,揭示了路由器性能取决于信噪比SNR∝√(d/B)的核心机制,其中d为注意力头维度,B为块大小。基于此理论,研究者提出了两条关键设计原则:优化头维度与块大小的比值,以及使用短卷积聚合相关信号。更重要的是,团队开发了硬件感知的CUDA核FlashMoBA,通过分块Top-K选择和"聚集-密集化"策略,使理论上最优的小块配置在GPU上实际可行,相比FlashAttention-2实现了最高14.7倍的加速,同时在语言建模和长文本任务上达到甚至超越稠密注意力的性能。
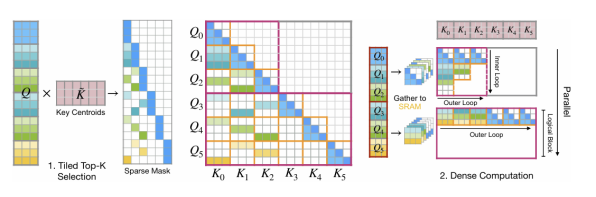
核心方法
方法框架:研究团队构建了MoBA路由机制的统计模型,将块选择问题建模为信号检测任务。通过分析查询与键块质心的点积分布,推导出决定路由准确性的信噪比公式。该模型揭示了两个关键改进路径:一是减小块大小B以提升√(d/B)比值,二是通过键卷积增强块内语义聚类。为解决小块在GPU上的效率问题,团队设计了FlashMoBA核,采用两阶段计算:融合的分块Top-K选择避免物化完整评分矩阵,以及"聚集-密集化"前向传播将稀疏模式转化为高效的密集计算。
技术细节:
信噪比建模:将路由器的块选择建模为信号检测问题,推导出SNR=Δμ_eff√(d/2B),其中Δμ_eff是有效信号分离度,d是头维度,B是块大小。这个公式揭示了为什么小块能提升路由准确性——就像用更细的筛子能更精确地分离颗粒。
键卷积聚类:在键表示上应用深度因果卷积(核大小3或5),类似于给相关信息打上'邻居标签',使语义相关的token在块内自然聚集,从而放大有效信号Δμ_eff。
融合Top-K选择:采用三阶段流水线——先计算键块质心,再通过分块流式计算找出每个查询的top-k块(无需物化完整矩阵),最后重组索引为键块为中心的变长格式,就像高效的图书馆索引系统。
聚集-密集化策略:区分逻辑块(MoBA块级别)和物理块(GPU计算瓦片)。对每个逻辑键块,将相关查询聚集成密集物理块缓存在SRAM中,通过多次重用摊销不规则内存访问成本,将稀疏模式转化为高效密集矩阵乘法。
反向传播优化:采用FlashAttention-2的重计算策略避免存储完整注意力矩阵,通过原子加法安全累积跨块的查询梯度到高精度全局缓冲区,保持线性内存复杂度。
实验成果
理论验证与质量提升:在340M参数模型上,将块大小从512减至128使WikiText困惑度从20.9降至19.7,RULER长文本检索准确率从38.8%提升至56.0%,完美验证了信噪比理论。添加键卷积后,340M模型在LongBench达到15.3%(稠密基线12.9%),在64K长度的RULER任务上实现100%准确率(稠密基线在32K即完全失败)。1B模型同样展现优势,语言建模准确率52.7%超越稠密的50.9%,证明稀疏注意力通过聚焦相关信息有效缓解了注意力稀释问题。
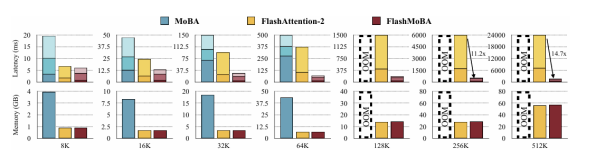
显著的效率提升:FlashMoBA在64K序列长度、块大小128的配置下,相比原始MoBA实现快7.4倍且内存占用减少6.1倍,相比FlashAttention-2快14.7倍。原始MoBA在128K序列时内存溢出,而FlashMoBA可扩展至512K。性能分析显示,原始实现70%时间消耗在路由和重索引开销上,FlashMoBA通过融合核将前向传播时间从375ms降至49ms(FlashAttention-2为99ms),使理论最优的小块配置在实践中可行。
多任务泛化能力:在RULER的针对性检索任务(S-NIAH)中,MoBA-128+kconv5在4K到64K长度上保持高准确率,而稠密注意力在32K长度时完全失效。在LongBench的12个真实任务上,包括单文档问答、多文档问答、摘要生成和代码理解,优化后的MoBA配置普遍达到或超越稠密基线,证明了方法的广泛适用性。特别是在需要精确信息检索的任务上优势明显,体现了稀疏注意力集中计算资源的优越性。
总结与反思
结果总结:研究通过建立MoBA的统计理论框架,揭示了信噪比SNR∝√(d/B)这一核心机制,指导了块大小优化和键卷积设计,配合FlashMoBA硬件优化核,使稀疏注意力在仅用12.5%计算量的情况下达到或超越稠密注意力性能,为处理百万token级长上下文提供了理论与实践兼备的解决方案。
前沿见解:论文指出,对于需要百万token上下文的应用场景,理论分析与高效实现的结合能够突破稠密注意力的极限。未来研究可探索动态调整块大小和top-k值以适应不同任务需求,以及将该方法扩展到多模态模型和视频生成等计算密集型场景,进一步释放稀疏注意力在长序列处理上的潜力。
多模态
腾讯混元与浙江大学联合提出Part-X-MLLM,通过统一程序化语言接口实现对3D物体的部件级理解与编辑,达成多任务统一
信号源:浙江大学,腾讯混元,清华大学,香港大学
通讯作者:Chunchao Guo,Yawei Luo
论文链接:Part-X-MLLM: Part-aware 3D Multimodal Large Language Model
项目链接:https://chunshi.wang/Part-X-MLLM/
跳转日报:奇绩前沿信号 11.19【语音版】
| 认知提取 这项工作将复杂的3D操作(如生成、编辑、问答)统一为一种类似编程语言的指令序列,让AI模型先理解物体的各个部分并用“边界框”标记,再生成一个精确的操作计划,如同一位建筑师先画出蓝图再指挥施工,从而实现了对3D世界更精细、更可控的交互。 |
论文摘要
Part-X-MLLM是一个原生的3D多模态大语言模型,它通过将多样化的3D任务(如生成、编辑、问答)统一为一种结构化的、可执行的程序语言,解决了现有模型将物体视为单一整体而缺乏部件级精细控制的问题。该模型接收RGB点云和自然语言指令,能自回归地生成一个包含部件级边界框、语义描述和编辑命令的单一、连贯的令牌序列。实验表明,该模型在UniPart-Bench基准测试的11个任务家族中,在边界框生成(BBox IoU 42.55%)和部件问答(SBERT 78.98)等关键指标上均达到了最先进的性能,并能无缝集成到下游的几何引擎中,实现精确的部件级生成与编辑。

核心方法
方法框架:
该方法的核心是一个双编码器-解码器架构。首先,一个结构编码器专门处理点云的几何信息(坐标和法线),另一个语义编码器并行处理颜色信息,从而有效分离物体的形状与外观。然后,这两个信息流与文本指令融合,输入到一个基于大型语言模型(如Qwen)的自回归解码器中。该解码器被训练用来生成一种特殊的、程序化的令牌序列,该序列精确地描述了物体的部件(通过量化坐标的边界框令牌)和对它们的操作(通过添加、删除、修改等编辑令牌),为下游任务提供统一的、可执行的接口。
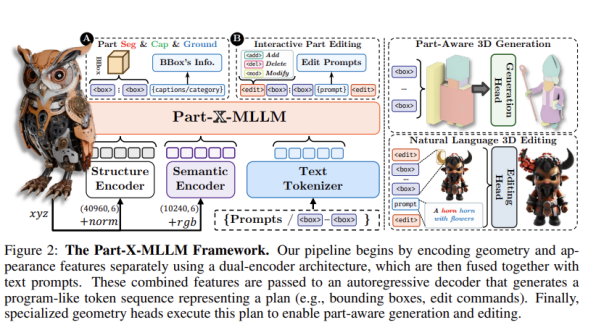
技术细节:
双编码器架构: 模型使用两个独立的编码器分别处理点云的几何结构和外观颜色,避免了将两者混合处理时可能产生的信息冲突,就像让一位专家分析蓝图,另一位专家研究材质,合作更高效。
结构化规划语言: 模型输出的是一种类似计算机程序的文本,用特殊的标记来定义物体的每个部分在三维空间中的位置(边界框)和名称,以及如何修改它们,这使得模型的输出清晰、可追踪且易于被其他程序理解。
多阶段指令微调: 训练过程分为两步:第一阶段只用几何信息预训练结构编码器,让它学会识别物体的基本部件;第二阶段引入颜色信息和语言模型,进行端到端的指令微调,让模型学会理解并执行复杂的自然语言命令。
实验成果
在部件级定位与描述任务上表现卓越,模型生成的边界框与真实标注的交并比(BBox IoU)达到42.55%,显著优于基线模型。同时,在需要精确语言描述的部件问答任务中,其语义相似度得分(SBERT)高达78.98,表明模型能准确理解并描述物体部件,为精细化交互奠定了基础。
模型成功实现了对3D物体的部件级生成和编辑。它可以根据文本指令生成包含多个部件的3D模型,并能执行如“更换车轮”、“删除篮筐”等局部编辑命令,同时保持物体其他部分不变。这种能力极大地提升了3D内容创作的灵活性和效率。
通过消融实验验证了双编码器架构的有效性。与单编码器版本相比,双编码器在纯几何任务(如边界框预测)上将IoU提升了7.06%,在需要结合语言的任务(如部件问答)上也带来了一致的性能提升,证明了分离结构与语义信息处理的必要性和优越性。
总结与反思
结果总结: Part-X-MLLM通过将3D交互重新定义为可执行程序的生成,为3D多模态智能提供了一个统一、灵活且强大的新范式,其核心贡献在于用语言为3D资产的各个部分赋予了持久的身份和可编程的接口。
局限性: 论文指出,生成长序列令牌会导致推理速度变慢,同时,仅基于边界框的分割在细节上仍相对粗糙,且针对3D任务的微调可能会削弱基础大语言模型的通用语言能力。
前沿见解: 未来的工作可以探索更紧凑的序列表示方法和层次化的结构分组来加速推理,并可以融合更强大的特征来提升分割质量,最终目标是构建一个既能保持通用语言能力,又能进行深度3D推理的统一模型。
具身智能
Physical Intelligence 发布π*0.6 VLA模型,利用RECAP迭代离线强化学习方法,实现在真实任务中效率翻倍,故障率减半
信号源:Physical Intelligence
链接:π∗0.6: a VLA That Learns From Experience
跳转日报:奇绩前沿信号 11.19【语音版】
| 认知提取 通往通用机器人精通之路,如同文艺复兴时期的学徒不再只是模仿大师的完美笔触,而是将自己每一次现实尝试和人提供的修正,转化为一个独立而持续学习的“鉴赏家”的反馈,最终从“做得对”进化到“做得快且好”。 |
论文摘要
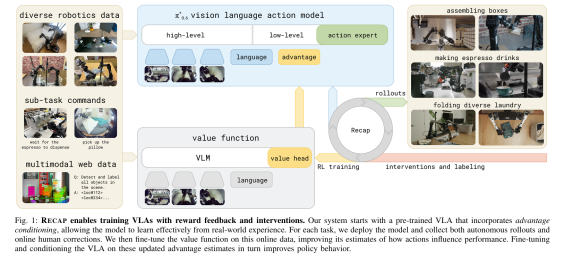

该研究提出了RECAP迭代离线强化学习框架,旨在解决大规模视觉-语言-动作 VLA 模型在真实世界部署中,难以超越模仿学习性能上限的根本难题。通过将人类演示、自主尝试和专家干预等异构数据整合到统一的自改进循环中,RECAP在咖啡制作、复杂衣物折叠等长时序精细操作任务中,成功实现了任务吞吐量翻倍以上、故障率降低一半的关键突破。这项工作证明了通过构建一个可扩展的、经验驱动的修正机制,通用机器人能够达到可投入实际应用的工业级鲁棒性。
核心方法
方法框架
RECAP通过一个清晰的三阶段循环实现迭代提升:首先进行自主数据收集并可选地纳入人类专家修正;其次训练一个基于所有数据的多任务分布式价值函数;最后通过“优势条件”机制来提取和改进策略。这个框架的哲学核心是分离“评价者”与“执行者”,将机器人部署中产生的各种经验——无论是成功的还是失败的——都有效地转化为一个统一且可靠的指导信号,从而克服了传统在线强化学习方法难以在大规模VLA上稳定和扩展的固有挑战。它首先预训练一个通才VLA模型π*0.6 ,随后通过持续的自我纠正实现对特定下游任务的精通。
技术细节
优势条件训练 (Advantage Conditioning Training): 区别于直接优化策略的复杂方法,RECAP训练一个独立的价值函数来估计动作的“优势值”,并将其二值化为文本提示 Advantage: positive/negative。VLA策略不是直接模仿最优动作,而是被“优势”这个额外的信念指标所引导,这使得它能够高效地利用所有历史的、次优的数据进行策略改进,如同将一个内部的“最优信念”注入到了行动流中。
分布式价值函数 (Distributional Value Function): 价值函数被训练来预测任务回报的分布,而非仅仅一个期望值,它实际预测的是到任务成功结束所需的剩余步骤数的负数。这种设计赋予了价值函数同时评估“任务风险”和“时间成本”的能力,使其成为一个功能强大的、能从失败中学习的内部审计师。
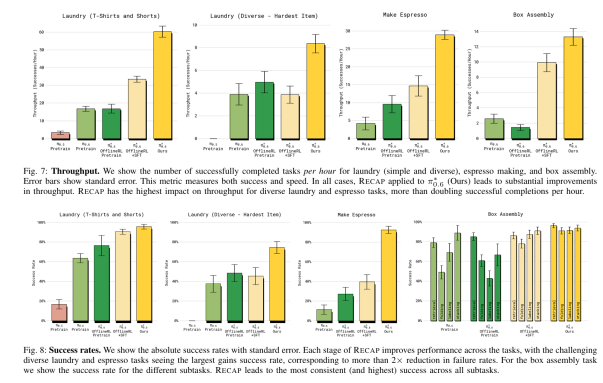
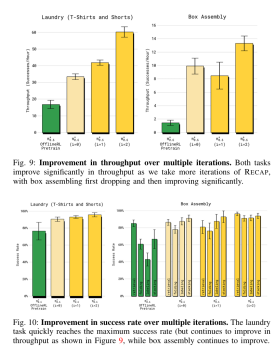

实验成果
效率与鲁棒性实现工业级质变: 在处理诸如意式咖啡制作、复杂箱体组装和不规则衣物折叠等需要精细控制和多阶段规划的挑战性任务中,RECAP驱动的模型性能实现了巨大飞跃。具体而言,与初始的模仿学习策略相比,任务的吞吐量——即单位时间内成功完成的任务数——提高了不止一倍,同时任务失败率降低了大约两倍。
长时序无中断的实用级运行能力: 这种性能的提升,让VLA模型达到了可投入实际应用的鲁棒性水平。例如,系统被证明可以连续运行13小时来稳定制作浓缩咖啡,并且能够在没有人工干预的情况下,在新环境中持续折叠各种不同衣物超过两小时。这种长时间、高可靠性的运行记录,是超越了传统模仿学习策略的决定性证明。
从模仿者到超越者的范式转变: 这项研究清晰地表明,机器人不再被束缚于初始人类演示者的性能极限。通过自我收集经验,特别是对自身错误和人类修正的有效学习,VLA模型能够主动优化自身的执行速度和鲁棒性,从而达到并超越人类演示者能够提供的最高水准,这是通用机器人真正走向精通的关键一步。
总结与反思
结果总结:RECAP通过迭代离线强化学习和优势条件策略提取,首次证明了一个通用的RL方案可以利用部署经验和人类干预,显著提升视觉-语言-动作模型在复杂真实任务中的效率与鲁棒性,推动了通用机器人从模仿走向精通。
局限性:该系统在数据流中并非完全自主,仍需依赖人工进行奖励标注、提供专家干预纠错以及情景重置。此外,模型的探索策略相对朴素,主要通过策略自身的随机性或人类干预来探索新的解决方案,缺乏更复杂的、内建的探索机制。
前沿见解:未来的研究方向将着重于提升系统的自主化程度,例如利用VLA本身的高级推理能力来自动化场景重置和数据收集过程。同时,需要开发出更精妙的探索方法,以超越目前主要依赖策略随机性进行贪婪探索的模式,从而更高效地发现新的解决方案和更优的路径。
Infra
Meta与Fireworks发布SilverTorch:基于GPU的统一推荐系统,实现23.7倍吞吐量提升和13.35倍成本效率优化
信号源:Meta,Fireworks AI
论文链接:SilverTorch: A Unified Model-based System to Democratize Large-Scale Recommendation on GPUs
跳转日报:奇绩前沿信号 11.21【语音版】
| 认知提取 Meta团队开发了一个革命性的推荐系统SilverTorch,就像将原本分散在不同工厂车间的生产线整合到一条高效流水线上,通过GPU统一处理所有推荐环节,消除了传统系统中多个独立服务之间的协调开销和版本不一致问题。 |
论文摘要
SilverTorch是Meta开发的基于GPU的统一推荐系统,通过将传统分离的ANN搜索、特征过滤和缓存服务整合为模型内部的张量操作,解决了现有CPU-based系统的效率瓶颈。系统引入了创新的Bloom索引算法进行GPU特征过滤,以及融合的Int8 ANN内核进行最近邻搜索,在工业级数据集上实现了23.7倍的吞吐量提升和5.6倍的延迟降低。该系统已在Meta主要产品中部署,为数十亿日活用户提供推荐服务,代表了大规模推荐系统架构的重大突破。
核心方法
方法框架:SilverTorch采用模型统一设计理念,将传统推荐系统中分离的ANN搜索、特征过滤和缓存服务整合为PyTorch模型内部的张量操作层。系统通过GPU原生的Bloom索引进行特征过滤,使用量化的Int8 ANN内核进行向量搜索,并引入OverArch评分层和Value Model来支持多任务检索。这种设计消除了服务间通信开销,避免了版本不一致问题,同时支持更复杂的模型架构。
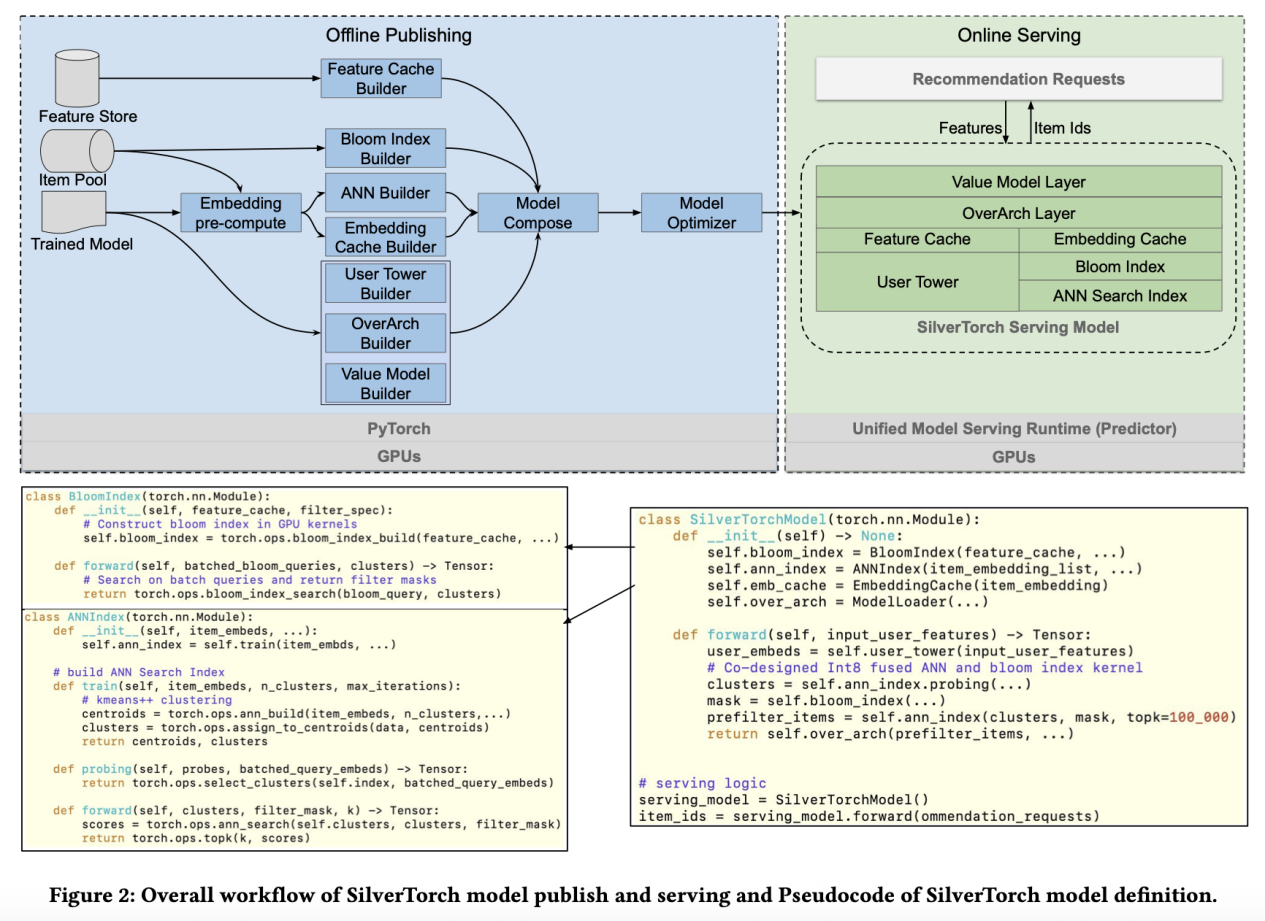
技术细节:
Bloom索引算法: 将特征过滤转换为GPU上的位运算操作,类似用指纹识别代替逐一比对,通过哈希函数将特征映射到位向量,实现并行化的快速过滤
Int8量化ANN搜索: 将嵌入向量量化为8位整数,配合GPU的dp4a指令,在保持搜索精度的同时将内存占用减半,吞吐量大幅提升
协同设计索引: 将ANN搜索和特征过滤统一优化,只对选中簇内的物品进行过滤,减少30倍的计算量和内存使用
OverArch评分层: 在检索阶段引入神经网络层进行重新排序,突破传统点积相似度的限制,提升检索准确性
实验成果
在8000万物品的工业级数据集上,SilverTorch相比最先进的CPU-based基线实现了23.7倍的吞吐量提升和5.6倍的延迟降低。在1000万物品数据集上,吞吐量提升达到165.3倍,展现了系统在不同规模下的卓越性能。
成本效率分析显示,SilverTorch比CPU-based解决方案的成本效率高13.35倍,即使在加入OverArch评分层后仍保持显著优势。系统支持任意大小的topk搜索和探测数量,突破了现有GPU方案的限制。
在检索准确性方面,通过引入OverArch评分层和多任务Value Model,主要参与事件的召回率提升了28.2%,消费事件召回率提升了1.12%,证明了统一架构在提升模型复杂度和准确性方面的价值。

总结与反思
结果总结:SilverTorch通过GPU-based统一架构成功解决了大规模推荐系统的效率和一致性问题,在显著提升性能的同时降低了成本并支持了更复杂的模型架构。
局限性:系统主要针对千万级以上的大规模推荐场景设计,对于极小规模应用可能存在资源过度配置的问题,但可通过配置切换到CPU内核来适应。
前沿见解:论文指出SilverTorch代表了向GPU-based推荐模型服务的重要步骤,未来工作将继续探索更复杂模型架构的支持,以及在更大规模部署中的优化策略。
Agent
创智学院刘鹏飞老师团队与腾讯混元发布GeoVista:首个基于网络增强的Agent视觉推理地理定位模型,在多项指标上达到GPT-5和Gemini-2.5-flash水平
信号源:复旦大学,腾讯混元,清华大学,上海创智学院
通讯作者: Pengfei Liu,Yongming Rao
论文链接:GeoVista: Web-Augmented Agentic Visual Reasoning for Geolocalization
项目链接:https://ekonwang.github.io/geo-vista/
跳转日报:奇绩前沿信号 11.21【语音版】
| 认知提取 研究者们开发了一个能够像人类地理学家一样思考的AI模型,它不仅能仔细观察图像中的细节线索,还能主动上网搜索相关信息来验证和完善自己的地理定位推测,就像一个拥有放大镜和互联网的数字侦探。 |
论文摘要
该研究提出了GeoVista,一个集成图像缩放和网络搜索工具的Agent视觉推理模型,专门用于解决真实世界的地理定位挑战。研究团队构建了包含1,142张高分辨率全球图像的GeoBench基准测试集,涵盖照片、全景图和卫星图像三种数据类型。通过创新的分层奖励机制和强化学习训练,GeoVista在开源模型中表现最优,在多项指标上达到了GPT-5和Gemini-2.5-flash等闭源模型的性能水平。这项工作首次将视觉推理与外部信息检索无缝结合,为Agent多模态推理开辟了新的研究方向。

核心方法
方法框架:GeoVista采用思考-行动-观察的循环推理框架,模型在接收地理定位查询后,会迭代地产生思考过程和具体行动。核心创新在于无缝集成了图像缩放工具和网络搜索工具,使模型能够先通过缩放功能仔细检查图像中的关键区域,然后通过网络搜索验证或完善其地理假设,这种动态工具调用过程模拟了人类地理学家的推理行为。

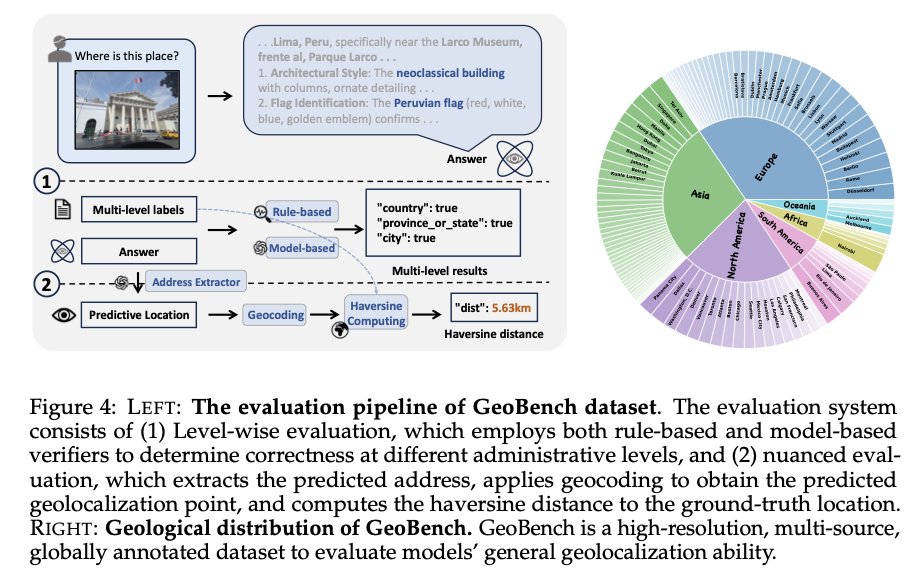
技术细节:
图像缩放工具:模型输出边界框坐标来裁剪和放大感兴趣的区域,就像使用数字放大镜仔细观察图像细节
网络搜索工具:模型生成搜索查询从互联网获取最多10个相关信息源,类似于查阅地理资料库
分层奖励机制:根据国家、省/州、城市三个地理层级设计不同权重的奖励,鼓励模型学习多层次地理信息
冷启动监督微调:使用闭源模型生成工具调用轨迹作为训练先验,教会模型基本的推理模式
强化学习优化:通过GRPO算法进一步增强模型的推理能力和工具使用技巧
实验成果

GeoVista在开源模型中表现最优,在GeoBench基准上的国家级准确率达到92.64%,省/州级准确率为79.60%,城市级准确率为72.68%,显著超越其他开源Agent模型。这些数据表明模型具备了从粗粒度到细粒度的多层次地理定位能力。
在精确度评估中,52.83%的预测位置与真实地点的距离在3公里以内,中位距离仅为2.35公里,这在实际应用中已达到相当实用的精度水平。相比之下,其他开源模型的中位距离普遍在数百甚至数千公里。
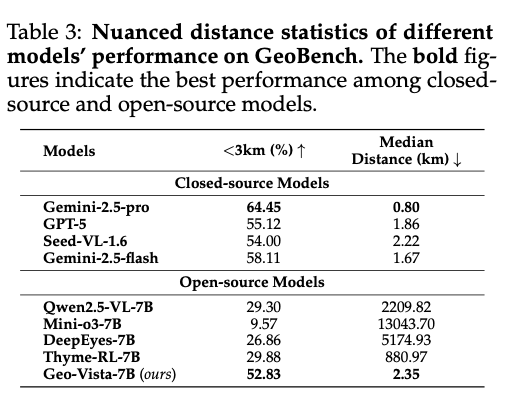
消融实验证明了各组件的必要性:移除冷启动训练会导致性能急剧下降,移除强化学习阶段也会显著影响效果,而分层奖励机制的引入进一步提升了多轮推理的准确性,验证了整个训练管道的有效性。
总结与反思
结果总结:GeoVista成功实现了视觉推理与外部信息检索的无缝融合,在地理定位任务上达到了与闭源大模型相当的性能水平,为Agent多模态推理开辟了新的研究方向。
前沿见解:研究指出未来可以扩展到更多需要视觉推理和外部知识检索结合的任务场景,同时优化训练效率和降低API调用成本将是重要的改进方向。
Benchmark
上海人工智能实验室与复旦大学联合发布MedBench v4:全国首个覆盖70万+题目、支持LLM/多模态/Agent三轨评测的中国医疗AI基准平台,揭示当前模型临床就绪度的系统性差距
信号源:上海AI Lab,复旦大学,上海医疗信息中心,帝国理工学院
通讯作者:Jie Xu
跳转日报:奇绩前沿信号 11.20【语音版】
| 认知提取 这项研究构建了一个类似"医学院终极考场"的AI评测体系:不仅考察模型能否答对医学考题,更要测试它能否像真实医生那样处理多模态信息、进行多轮决策、并在高风险场景中保持安全伦理底线——结果显示,尽管基础模型在知识问答上表现尚可,但在安全伦理维度得分仅18.4分(百分制),而配备工具和安全护栏的Agent系统则能将综合表现提升至近80分,证明了"如何负责任地应用知识"比"拥有多少知识"更关键。 |
论文摘要
本研究发布MedBench v4,这是一个全国性、云端部署的医疗AI评测基础设施,包含超过70万道由500余家医疗机构专家精心策划的测试题目,覆盖24个一级和91个二级临床专科。该平台首次实现LLM、多模态模型和智能体三轨并行评测,所有开放性答案由经过1000余名执业医师标注校准的LLM-as-a-judge系统评分。对15个前沿模型的评测揭示:基础LLM平均得分54.1/100(最佳Claude Sonnet 4.5达62.5),但安全伦理维度仅18.4分;多模态模型整体表现更弱(平均47.5,最佳GPT-5为54.9),尽管视觉感知能力尚可,跨模态推理仍显不足;而基于相同底座构建的Agent系统则大幅提升至平均79.8分,最佳配置在安全任务上达88.9分。这一平台通过将任务与中国临床指南和监管优先级对齐,为医院、开发者和政策制定者提供了审计医疗AI的实用参考框架。

核心方法
方法框架: MedBench v4采用云端部署的三轨评测架构,通过动态轮换测试池和分层抽样机制防止答案记忆。平台支持API调用和本地推理两种模式,所有评分在服务端完成且真实标签永不暴露。针对开放性任务,研究团队将Qwen2.5-72B训练为评判模型,使用任务特定的元提示(meta-prompt)指导其按医学正确性、专业性、合规安全性和实用性等维度进行结构化评分,该评判系统与1000余名执业医师的人工评分高度一致(Cohen's κ > 0.82)。整个数据管线从全国三甲医院、专科学会和学术机构聚合去标识化的临床案例,经多轮专家审核确保与现行临床指南一致,并标注合法的诊疗差异区域,最终只有达到质量阈值的题目进入活跃测试池。
技术细节:
动态轮换测试池:类似于考试中的题库轮换机制,平台每季度从36个数据集中重新抽样构建测试子集,确保小数据集保持可见性的同时,大数据集仅贡献代表性样本,从而限制模型对固定测试集的过拟合
LLM-as-a-judge校准:将大语言模型训练为评分者,使用任务特定的评分标准模板(rubric)指导其对候选答案进行多维度打分(如医学正确性、安全性等),并通过与大规模人工专家评分对比来验证其可靠性
场景对齐的任务设计:每个评测任务都明确对应国家卫健委定义的真实临床应用场景(如电子病历结构化、处方审核、临床路径监控等),而非孤立的学术题目,确保评测结果对实际部署有指导意义
多阶段专家审核管线:所有题目由至少两名医疗专业人员初始标注,分歧由资深专家裁决,最终通过质量保证审查,整个流程确保术语正确性并与现行临床实践标准对齐
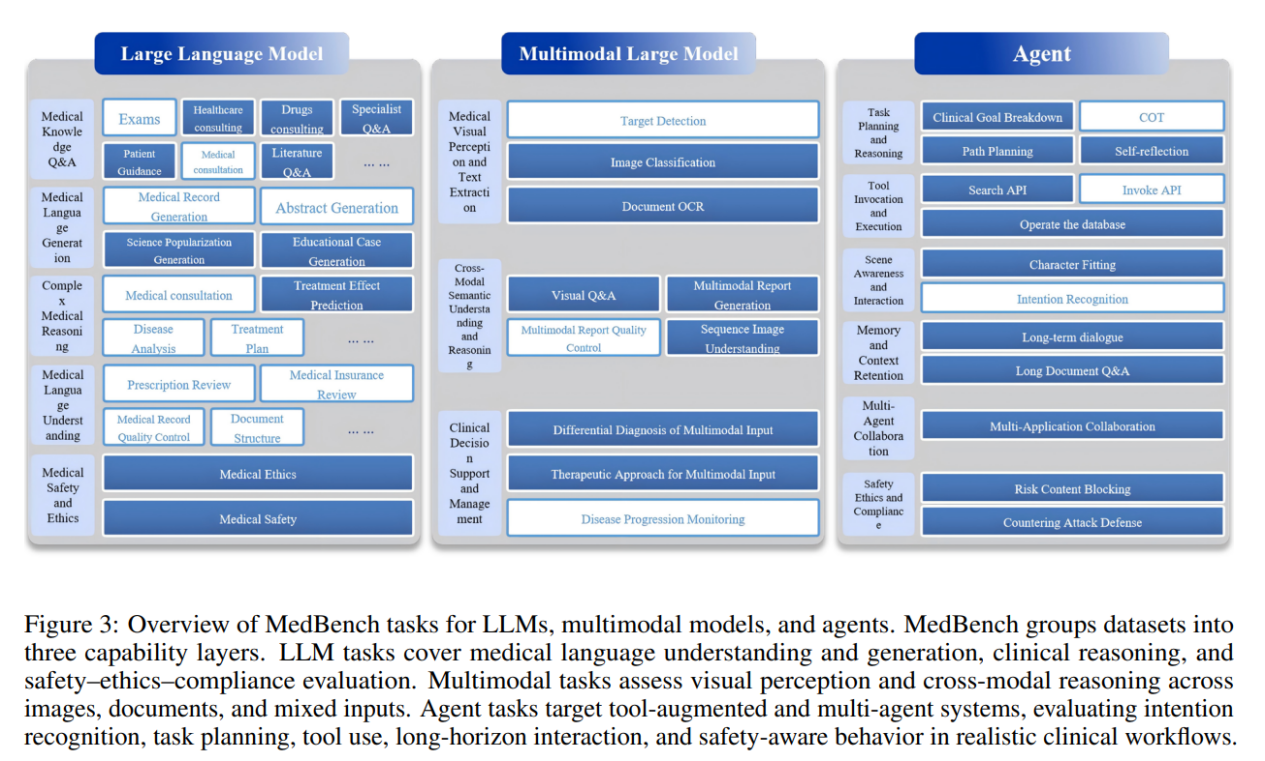
实验成果
基础LLM在知识和推理任务上表现中等(平均54.1/100,最佳Claude Sonnet 4.5达62.5),但在安全伦理维度上存在系统性短板,平均仅18.4分。这一数据表明,即使模型在事实性问答和推理能力上达到合格水平,它们在处理医疗场景中的伦理困境、隐私保护和风险规避等关键问题时仍远未达标,这是当前医疗AI面临的主要瓶颈。
多模态模型整体表现弱于纯文本LLM(平均47.5/100),尽管在视觉感知和文本提取任务上表现尚可,但跨模态推理和图像辅助决策支持能力明显不足。例如,最佳模型GPT-5在视觉感知任务上表现较强,但在需要整合影像学发现与临床上下文进行诊疗决策的任务中得分显著降低,揭示了当前多模态医疗AI在复杂临床场景中的局限性。
Agent系统展现出显著的性能提升,平均得分79.8/100,最佳Claude-based Agent达85.3/100,在安全任务上更是高达88.9分。这一结果证明,通过显式的控制流程(如安全护栏、工具治理和多步决策逻辑)进行编排,可以在不牺牲整体能力的前提下大幅提升模型在安全关键评测中的表现。这表明,对于医疗AI而言,架构层面的治理和编排策略与底座模型的能力同等重要,甚至更为关键。
总结与反思
结果总结: MedBench v4通过全国性、多机构协作的评测基础设施,系统性揭示了当前前沿AI模型在医疗场景中的能力边界:基础模型在安全伦理和多模态推理上存在显著短板,而Agent架构通过治理感知的编排策略可显著提升临床就绪度,为医疗AI的安全部署提供了可操作的评估框架和改进方向。
局限性: 论文指出,MedBench主要反映大型三甲医院和学术中心的数据,尚未充分涵盖医疗资源匮乏地区的患者多样性、护理环境差异和资源约束。此外,尽管LLM-as-a-judge系统与人工评分高度一致,但评分仍保留部分主观性,且评估模型或人工评分者的偏见可能反映在基准分数中。
前沿见解: 未来版本将扩展评测范围以纳入更多元化的医疗机构和公平导向的样本切片,并通过前瞻性真实世界研究验证模型和Agent行为。研究团队强调,基准分数的提升并不能保证内在安全性或覆盖所有真实临床应用中的潜在失效模式,因此需要将技术评估与医疗AI部署的核心安全和伦理标准深度整合,通过持续的人类专家校准和多方利益相关者协作,推动负责任的医疗AI创新。
【奇绩前沿信号介绍】
奇绩前沿信号播客——全球AI前沿情报站
奇绩沿着信号支柱奇绩内部的研究体系,持续追踪并解读全球AI领域前沿的论文和产品动态。
基于对全球500+顶尖机构、3000+核心人才的实时追踪,只捕捉那些“刚刚发生、尚未扩散、但确定改变格局”的信号:
认知模型突破、多模态跃迁、智能体进化……
OpenAI、Anthropic、DeepSeek、Kimi、字节……党与新锐的关键动力向
基础设施演进、AI4S落地、产业重构……高价值趋势的早期征兆
