Submitted by dkliang 80 Generation Models Know Space: Unleashing Implicit 3D Priors for Scene Understanding H-EmbodVis 142 4
Submitted by syxbb 60 SAMA: Factorized Semantic Anchoring and Motion Alignment for Instruction-Guided Video Editing BAIDU 38 3
Submitted by lanikoworld 48 3DreamBooth: High-Fidelity 3D Subject-Driven Video Generation Model Yonsei University 28 3
Submitted by taesiri 44 Nemotron-Cascade 2: Post-Training LLMs with Cascade RL and Multi-Domain On-Policy Distillation NVIDIA 2
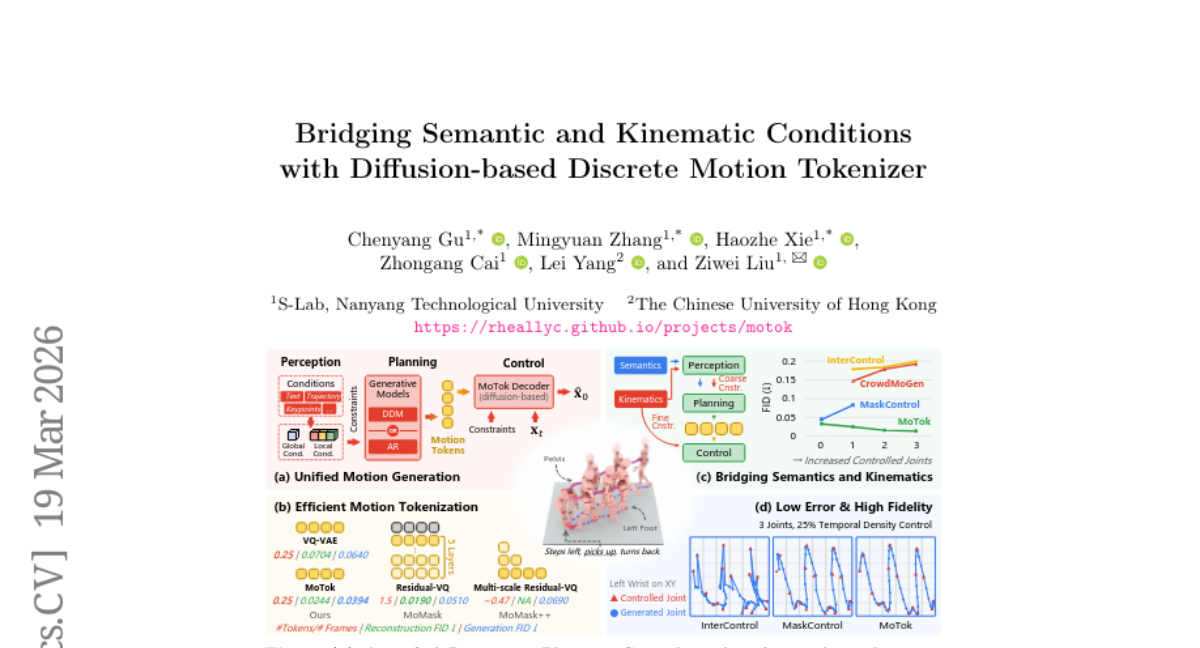
Submitted by hzxie 36 Bridging Semantic and Kinematic Conditions with Diffusion-based Discrete Motion Tokenizer MMLab@NTU 9 3
Submitted by Epiphqny 29 Cubic Discrete Diffusion: Discrete Visual Generation on High-Dimensional Representation Tokens The University of Hong Kong 40 2
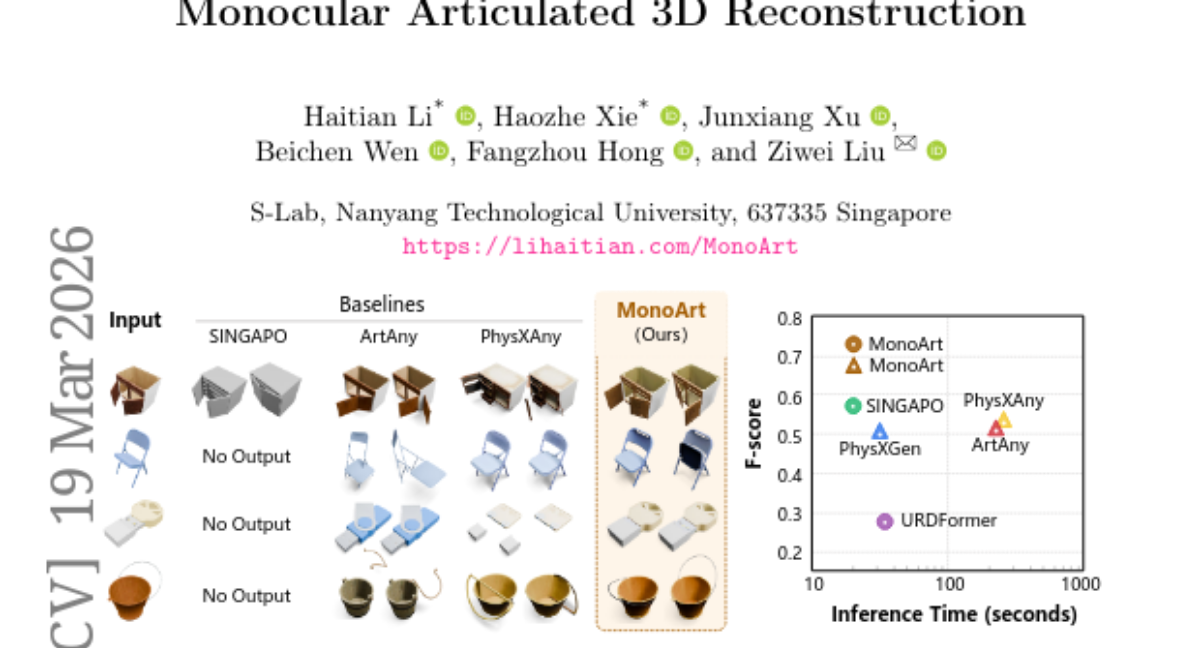
Submitted by hzxie 29 MonoArt: Progressive Structural Reasoning for Monocular Articulated 3D Reconstruction MMLab@NTU 31 3
Submitted by KD-TAO 27 LVOmniBench: Pioneering Long Audio-Video Understanding Evaluation for Omnimodal LLMs · 16 authors 32 2
Submitted by Geralt-Targaryen 23 F2LLM-v2: Inclusive, Performant, and Efficient Embeddings for a Multilingual World CodeFuse AI 2
Submitted by bing-li-ai 21 ReactMotion: Generating Reactive Listener Motions from Speaker Utterance · 8 authors 169 3
Submitted by Jungang 20 AndroTMem: From Interaction Trajectories to Anchored Memory in Long-Horizon GUI Agents · 28 authors 2
Submitted by liyn20 17 Cognitive Mismatch in Multimodal Large Language Models for Discrete Symbol Understanding · 13 authors 2
Submitted by HenghuiDing 16 EffectErase: Joint Video Object Removal and Insertion for High-Quality Effect Erasing FudanCVL 38 2
Submitted by DogNeverSleep 15 VTC-Bench: Evaluating Agentic Multimodal Models via Compositional Visual Tool Chaining · 12 authors 30 2
Submitted by d3tk 13 Tinted Frames: Question Framing Blinds Vision-Language Models University of British Columbia 2 2
Submitted by spapi 13 SimulU: Training-free Policy for Long-form Simultaneous Speech-to-Speech Translation FBK-MT 2
Submitted by taesiri 7 ProRL Agent: Rollout-as-a-Service for RL Training of Multi-Turn LLM Agents NVIDIA 34 1
Submitted by KevinQu7 6 Loc3R-VLM: Language-based Localization and 3D Reasoning with Vision-Language Models Microsoft 2
Submitted by whj363636 5 MHPO: Modulated Hazard-aware Policy Optimization for Stable Reinforcement Learning Tencent 2
Submitted by delyanboychev 4 OSM-based Domain Adaptation for Remote Sensing VLMs Institute for Computer Science, Artificial intelligence and Technology 2
Submitted by taesiri 3 Reasoning over mathematical objects: on-policy reward modeling and test time aggregation · 21 authors 1
Submitted by gagan3012 1 What Really Controls Temporal Reasoning in Large Language Models: Tokenisation or Representation of Time? · 4 authors 1 2
Submitted by MohammadJRanjbar 1 PARSA-Bench: A Comprehensive Persian Audio-Language Model Benchmark · 5 authors 2
Submitted by nkthiroto 1 VID-AD: A Dataset for Image-Level Logical Anomaly Detection under Vision-Induced Distraction · 8 authors 4 2
Submitted by lyf07 1 Mending the Holes: Mitigating Reward Hacking in Reinforcement Learning for Multilingual Translation · 4 authors 5 2
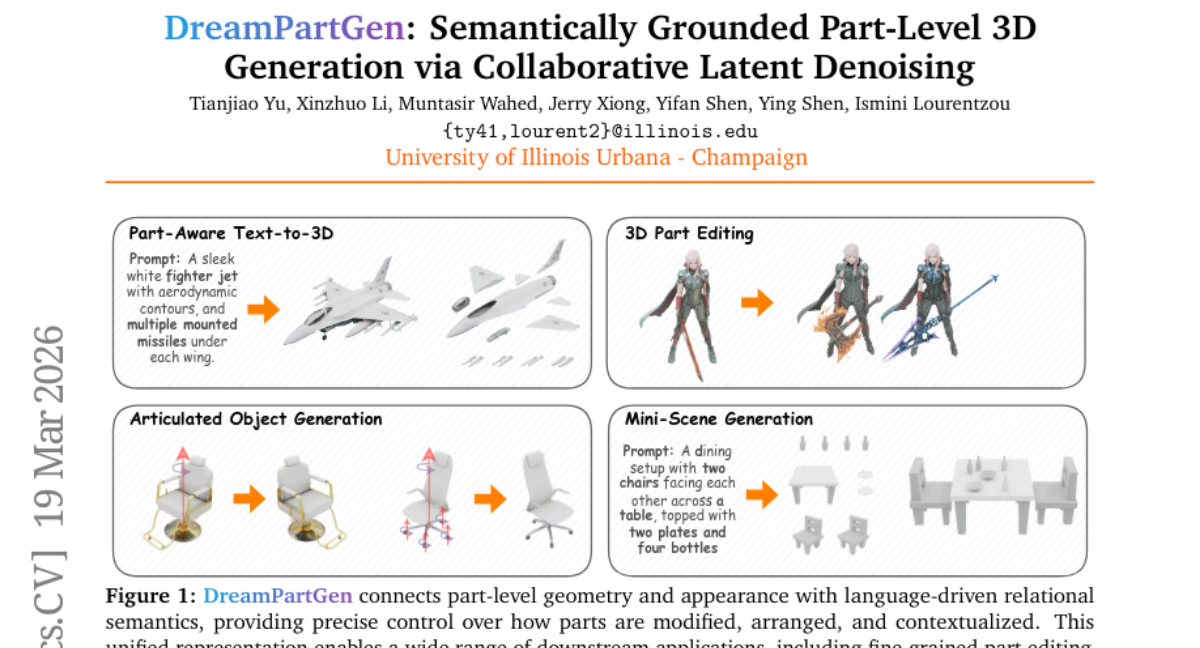
Submitted by isminoula - DreamPartGen: Semantically Grounded Part-Level 3D Generation via Collaborative Latent Denoising Perception and LANguage Lab 2


 dkliang
dkliang