
SDOFMv2: A Multi-Instrument Foundation Model for the Solar Dynamics Observatory
SDOFMv2 is an advanced multi-instrument foundation model for analyzing Solar Dynamics Observatory (SDO) data, designed to drive large-scale, data-driven heliophysics research. This model is a Masked Autoencoder (MAE) pretrained on the SDOMLv2 dataset.
This model card is for the pretrained MAE checkpoint, ready for finetuning on downstream tasks.
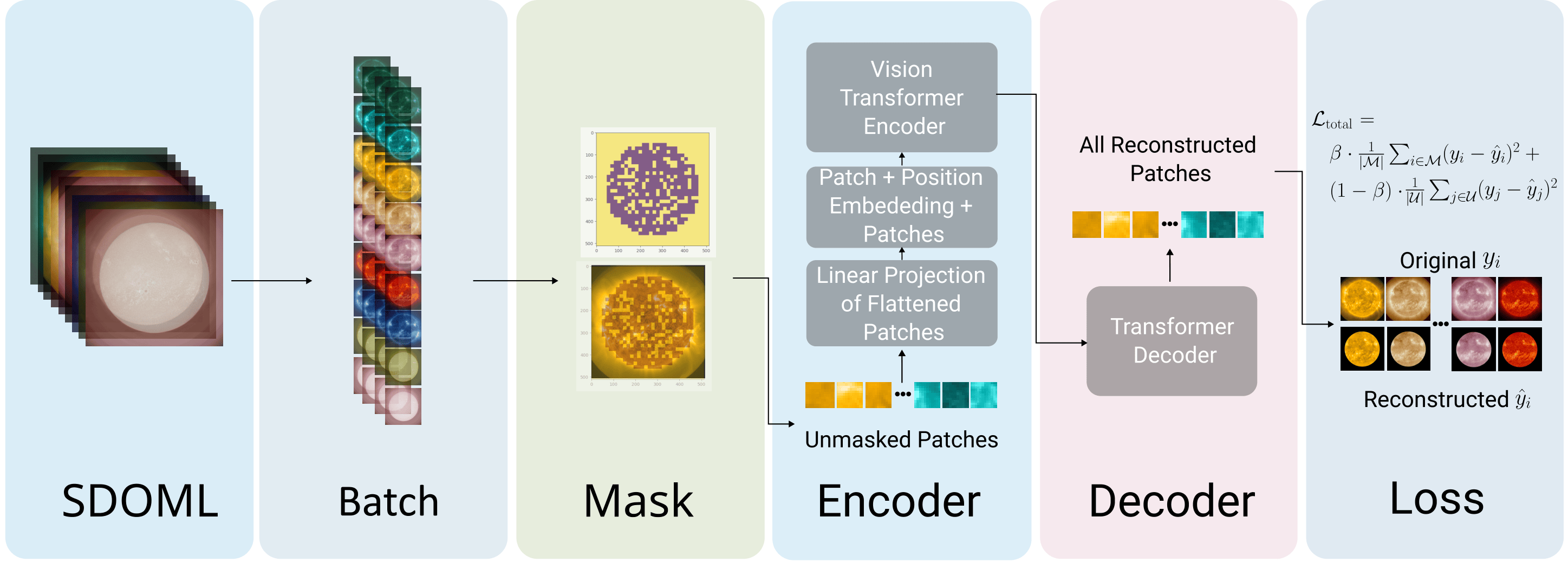 A Masked Autoencoder (MAE) built on a Vision Transformer (ViT) backbone is used for pretraining. The encoder processes a subset of image patches, and the decoder reconstructs the full image.
A Masked Autoencoder (MAE) built on a Vision Transformer (ViT) backbone is used for pretraining. The encoder processes a subset of image patches, and the decoder reconstructs the full image.
Model Details
- Model type: Masked Autoencoder (MAE) with a Vision Transformer (ViT) backbone.
- Pretrained on: SDOMLv2 dataset, containing multi-instrument data from the Solar Dynamics Observatory (AIA and HMI instruments).
- Primary intended use: Feature extraction and finetuning for downstream heliophysics tasks such as solar flare prediction, coronal mass ejection detection, and physical parameter estimation.
- License: MIT
How to Use
Installation
For installation instructions, see the Getting Started guide in the documentation.
Loading the Pretrained Model
from huggingface_hub import hf_hub_download
from sdofmv2.core import MAE
# Download and load the pretrained checkpoint
# AIA model (9 EUV channels)
ckpt_path = hf_hub_download(repo_id="Joaggi/sdofmv2", filename="sdofmv2-mae-aia-512px.ckpt")
model = MAE.load_from_checkpoint(ckpt_path)
# HMI model (3 magnetogram channels)
ckpt_path = hf_hub_download(repo_id="Joaggi/sdofmv2", filename="sdofmv2-mae-hmi-512px.ckpt")
model = MAE.load_from_checkpoint(ckpt_path)
model.eval()
Model Variants
| Checkpoint | Instrument | Channels |
|---|---|---|
sdofmv2-mae-aia-512px.ckpt |
AIA | 94 Å, 131 Å, 171 Å, 193 Å, 211 Å, 304 Å, 335 Å, 1600 Å, 1700 Å |
sdofmv2-mae-hmi-512px.ckpt |
HMI | Bx, By, Bz |
Feature Extraction
The encoder outputs patch-level embeddings that can be used as features for downstream tasks:
import torch
# Input shape: (batch_size, num_channels, height, width)
# num_channels = 9 (AIA) or 12 (AIA + HMI)
x = torch.randn(1, 9, 512, 512)
with torch.no_grad():
features = model.forward_encoder(x, mask_ratio=0.5)
# Output shape: (1, N, D) — N patch tokens, D embedding dimension
print(features.shape)
Finetuning
To finetune SDOFMv2 on a downstream task, attach a task head to the extracted features:
import torch.nn as nn
class SDOFMv2Classifier(nn.Module):
def __init__(self, backbone, num_classes=2):
super().__init__()
self.backbone = backbone
self.head = nn.Linear(backbone.embed_dim, num_classes)
def forward(self, x):
features = self.backbone.forward_encoder(x, mask_ratio=0.0) # (B, N, D)
pooled = features.mean(dim=1) # global average pool → (B, D)
return self.head(pooled)
classifier = SDOFMv2Classifier(model, num_classes=2) # e.g., flare / no-flare
For complete finetuning scripts, see the GitHub repository.
Downstream Applications
The pretrained SDOFMv2 can be finetuned for various tasks:
- Solar Flare Prediction: Use the extracted features as input to a classifier to predict the likelihood of solar flares.
- Missing Data Imputation: The MAE's decoder can be used to reconstruct missing or corrupted regions in SDO images.
- Solar Wind Forecasting: Correlate full-disk solar images with solar wind parameters.
For detailed examples and finetuning scripts, please refer to the Notebooks in the original GitHub repository.
Training Data
The model was pretrained on the SDOMLv2 dataset, which contains:
| Component | Instrument | Data Type | Approx. Size | Description |
|---|---|---|---|---|
aia |
AIA | EUV Images | ~7.2 TB | 9 extreme ultraviolet channels capturing the solar atmosphere |
hmi |
HMI | Magnetograms | ~713 GB | 3-component vector magnetic field for the solar photosphere |
Due to its size, the data was streamed from NASA's HDRL S3 bucket during training. For more information on accessing the dataset, see the data preparation guide.
Evaluation Results
The model demonstrates high-quality reconstruction of SDO images, indicating a robust understanding of solar features.

Row 1: Ground-truth images. Row 2: Reconstructions at 0% masking ratio. Row 3: Reconstructions at 50% masking ratio.
Citation
If you find SDOFMv2 useful in your research, please cite the original work:
@misc{sdofmv2,
author = {Hong, Jinsu and Martin, Daniela and Gallego, Joseph},
title = {SDOFMv2: A Multi-Instrument Foundation Model for the Solar Dynamics Observatory with Transferable Downstream Applications},
year = {2026},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {\url{https://github.com/Joaggi/sdofmv2}},
note = {Jinsu Hong, Daniela Martin, and Joseph Gallego contributed equally to this work}
}
Acknowledgments
This work builds on the SDOFM framework. We thank the creators of SDOMLv2 for the curated training data and the NASA Solar Dynamics Observatory mission for their open data policy.